 Hackatua - February 19, 2023
Hackatua - February 19, 2023Python3 HTTP Directory Lister with remote dictionary
How to develop an HTTP directory lister in Python3 only with native libraries and a remote dictionary
On many occasions, after having successfully breached a machine, we reach new subnets to be explored and we are forced to work from the breached machine. In contrast to the machine from which we attacked, there are probably no pentesting tools on the compromised machine, so we will have to find a way to do our reconnaissance without them.
In these scenarios where we cannot install tools, we have to use our imagination and build our own to suit the circumstances. For example, if it is a Linux machine, we usually have the Python interpreter at our side since it is installed by default in several distributions. This allows us to quickly develop and run tools that we build using that language.
In this post we will see how to build a Python3 script that allows us to list the existing directories and files of a web application using a dictionary found in a remote URL, and without the need to install any additional dependencies or libraries to those that already come by default with Python.
Developing the script
The script consists of 3 main parts: the generation of the URLs dictionary, the checking of the existence or non-existence of the generated URLs, and the parsing of the parameters with which we call the script and its execution.
The script will support augmenting the dictionary used by adding file extensions to the different words in it, and will make use of several threads when verifying the existence of the resources. If we don't use multithreading the process could be very slow.
To do this we start by defining the interpreter, adding the dependencies, and some necessary variables:
#!/usr/bin/env python3 from urllib.request import urlopen, Request from urllib.error import HTTPError from queue import Queue from typing import List from re import search import sys from threading import Thread from argparse import ArgumentParser, RawDescriptionHelpFormatter AGENT = "Mozilla/5.0 (X11: Lunux x86_64: rv:19.0) Gecko/20100101 Firefox/19.0" DEFAULT_THREADS = 10
The most important libraries we use are urllib to perform the HTTP requests, queue and threading to handle multithreading, and argparse to define the script call parameters. We also define the user agent that we will use in our requests.
We generate the dictionary
In this first part we will generate the dictionary that our script will use. This dictionary is obtained by adding the file extensions specified when calling the script to a dictionary obtained via HTTP (also specified in the script call).
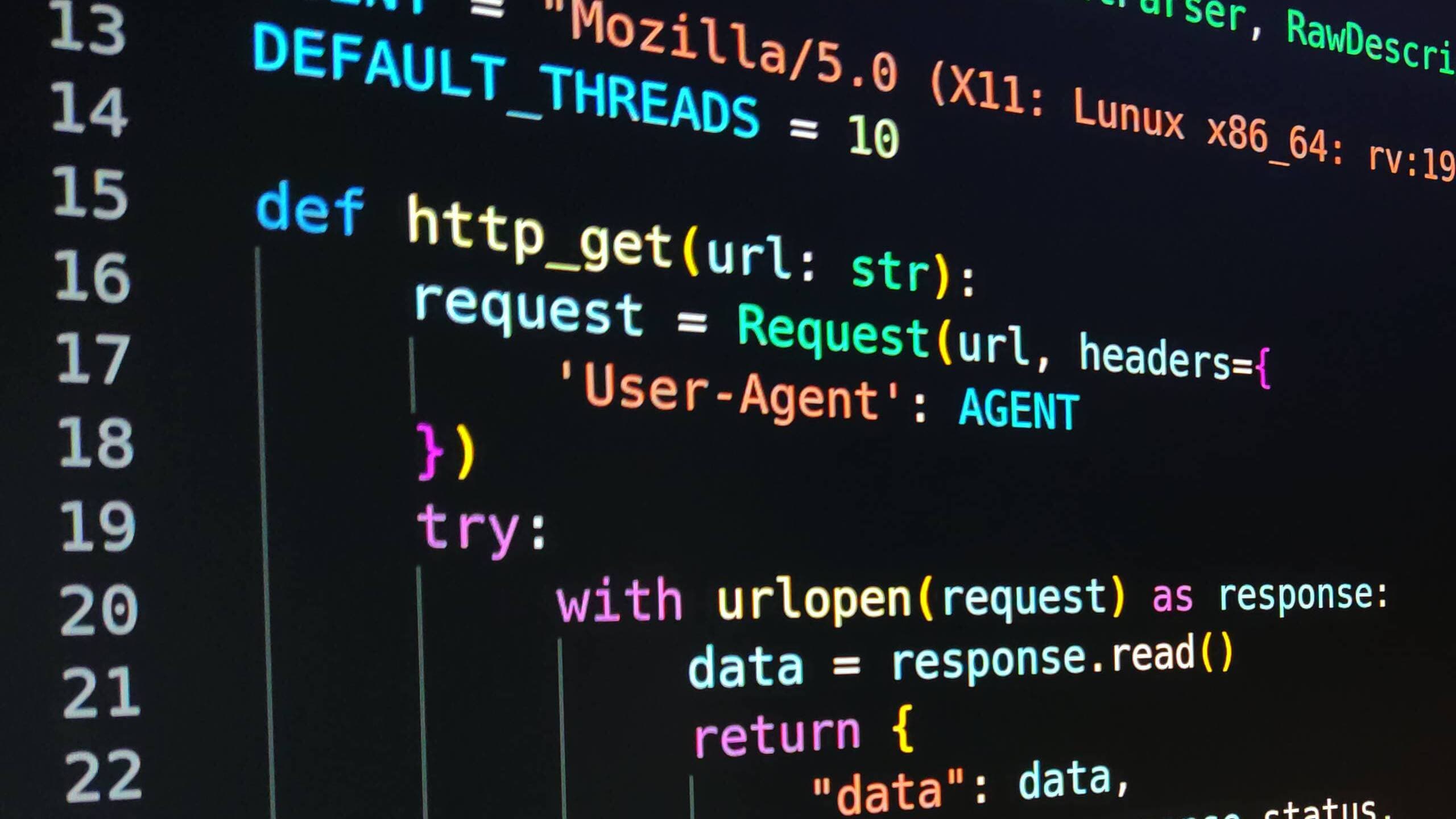
The first thing we need is a function that allows us to make a GET request via HTTP. This function will be used both to obtain the dictionary and then to check if the directories and files exist in the web application:
def http_get(url: str): request = Request(url, headers={ 'User-Agent': AGENT }) try: with urlopen(request) as response: data = response.read() return { "data": data, "status": response.status, "url": response.url } except HTTPError as error: return { "status": error.code, }
In this code fragment we use the urlib library to build an HTTP request to which we are going to add the User-Agent header, since many services verify that it is a User Agent of an existing browser. In addition we handle possible HTTP errors by returning only the status code returned by the server.
The next thing we have to do is to use this method to get the dictionary of the URL entered by the user:
def get_dictionary(remote_dictionary_url: str) -> List[str]: response = http_get(remote_dictionary_url) data = response["data"] return data.decode("UTF-8").split("\n")
Using the function defined above we get the dictionary, decode it using the UTF-8 encoding, and create a list with one element for each of the dictionary lines (we expect a dictionary where each word is separated by a line break).
Now that we have this ready, it is time to add the extensions to the words in the retrieved dictionary using the get_dictionary method:
def has_extension(word: str) -> bool: return search("(\.\w+)$", word) def get_dirs(remote_dictionary_url: str, extensions: List[str]) -> Queue: print(f"[+] Retrieving wordlist from {remote_dictionary_url} ...") dictionary = get_dictionary(remote_dictionary_url) print(f"[+] Loaded {len(dictionary)} words from {remote_dictionary_url}") print(f"[+] Building dictionary with extensions {extensions} ...") words = Queue() for raw_word in dictionary: word = raw_word.strip() if len(word) == 0 or word.startswith("#"): continue words.put(word) if not has_extension(word) and len(extensions): for extension in extensions: words.put(f"{word}.{extension}") print(f"[+] The final dictionary has approximately {words.qsize()} words") return words
In this method we obtain the dictionary and create an object of type Queue, which will allow us later, by using threads, to consume it in a safe way.
We add all the words from the dictionary to our Queue by eliminating the invalid ones, that is, eliminating those that are comments (those that begin with #) or that have no length. For each valid word, we generate an additional word for each file extension.
Listing the directories and files
With what we have done above we already have ready the part of obtaining the dictionary that will be used during the attack, so the following is to create the function that verifies if the file or directory exists. For it we will make a function that will take an element of the queue and will verify if it exists:
def dir_test_handler(target_url: str, words: Queue): while not words.empty(): url = f"{target_url}/{words.get()}" print(f"[+] {words.qsize()} dirs left" + " " * 10, end='\r') try: response = http_get(url) except: continue status = response["status"] if status >= 200 and status < 300: final_url = response["url"] if url == final_url: print(f" [*] [{status}]: {url}") else: print(f" [*] [{status}]: {url} -> {final_url}") elif status == 401 or status == 403: print(f" [!] [{status}]: {url}") elif status >= 400 and status < 600: continue else: print(f" [?] [{status}]: {url}")
This function does the following:
- Generates the final URL of the file or directory.
- Shows how many urls are left to test
- It makes the request and discards if there is any uncontrolled error.
- Based on the status we show the result on the screen.
In case of a 2XX, it may be because the resource is in the generated url, or because there has been a redirection. In that case the url and the final_url are different so we show that there has been a redirection.
The 4XX and 5XX we ignore, unless they are a 401 or 403, since they are URLs that we could get access to if we figure out how to authenticate.
And finally, we show any status code other than these mentioned above, as it is something unusual that may be worth investigating.
Define the script parameters
The next thing we have to do is to define with which parameters the script will be able to be executed. I would be interested in being able to provide:
- URL of the target machine against which we want to launch the attack.
- URL of the dictionary we want to use as a base
- Number of threads to use
- File extensions with which to extend the dictionary.
To define these parameters we will use the argparse library, which allows us to define all these parameters in a simple way, and automates both the parsing and the option to show help information:
def parse_arguments(): example_text = "\n".join([ "usage:", " python3 %(prog)s -u http://10.0.0.103 -d https://..../directory-list-2.3-medium.txt -e html,txt -t 20", " python3 %(prog)s -t -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt" ]) parser = ArgumentParser( description="HTTP directory lister program that retrieves the wordlist through HTTP and only uses default Python libraries", formatter_class=RawDescriptionHelpFormatter, epilog=example_text ) parser.add_argument( "-u", "--url", type=str, help="Target URL (-u http://10.0.0.103)", required=True ) parser.add_argument( "-d" ,"--dict", type=str, help="Dictionary URL (-d -d https://.../directory-list-2.3-medium.txt)", required=True ) parser.add_argument( "-t", "--threads", type=int, help="Number of threads (-t 20)", default=DEFAULT_THREADS, required=False ) parser.add_argument( "-e", "--ext", type=str, help="File extensions to test, separated by \",\" (-e html,txt)", default="", required=False ) return parser.parse_args()
As we can see we have defined each of the arguments with their characteristics, and a little help on how to use them.
Now we only have to define the entry point of the program:
def main(): args = parse_arguments() dirs = get_dirs(args.dict, args.ext.split(",")) print(f"[+] Ready to do directory discovery on {args.url}") print("[+] Press enter to continue") sys.stdin.readline() print(f"[+] Spawning {args.threads} threads...") for _ in range(DEFAULT_THREADS): thread = Thread( target=dir_test_handler, args=(args.url, dirs, ) ) thread.start() if __name__ == "__main__": try: main() except KeyboardInterrupt: print("[!] Exiting...") sys.exit(0)
In our main function we parse the parameters with which we have called the script, generate the dictionary, display the information of the attack to be performed and wait for the user's confirmation. After the confirmation we create the number of threads indicated and the attack begins.
In addition, the keyboard exception produced when pressing Ctrl + c is captured in order to exit the program without seeing the exception.
With this last one we would already have the program ready to execute. The complete source code is available at:
Testing the script
The first thing we can do is to look at the help info of our script:
python3 remote-dictionary-dirlister.py -h # or python3 remote-dictionary-dirlister.py --help
Result:
usage: remote-dictionary-dirlister.py [-h] -u URL -d DICT [-t THREADS] [-e EXT] HTTP directory lister program that retrieves the wordlist through HTTP and only uses default Python libraries options: -h, --help show this help message and exit -u URL, --url URL Target URL (-u http://10.0.0.103) -d DICT, --dict DICT Dictionary URL (-d -d https://.../directory-list-2.3-medium.txt) -t THREADS, --threads THREADS Number of threads (-t 20) -e EXT, --ext EXT File extensions to test, separated by "," (-e html,txt) usage: python3 remote-dictionary-dirlister.py -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt -e html,txt -t 20 python3 remote-dictionary-dirlister.py -t -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt
Now that we have verified that the help works, what we can do is to test the script against the Vulnhub's Naguini machine, which we have already solved here.
To do this we deploy the machine and run the script. In this case we are going to use the dictionary directory-list-2.3-medium from Daniel Miessler's SecLists repository, with 20 threads, and with html and txt file extensions.
remote-dictionary-dirlister.py -u http://10.0.0.103 -d https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt -e html,txt -t 20
Result:
[+] Retrieving wordlist from https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt ... [+] Loaded 220561 words from https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt [+] Building dictionary with extensions ['html', 'txt'] ... [+] The final dictionary has approximately 661635 words [+] Ready to do directory discovery on http://10.0.0.103 [+] Press enter to continue [+] Spawning 20 threads... [*] [200]: http://10.0.0.103/index.html [*] [200]: http://10.0.0.103/note.txt [*] [200]: http://10.0.0.103/joomla -> http://10.0.0.103/joomla/ [!] [403]: http://10.0.0.103/server-status
If we compare it with what we obtained with Gobuster in the Nagini machine resolution our script has nothing to envy it. This was the result obtained:
/index.html (Status: 200) [Size: 97] /note.txt (Status: 200) [Size: 234] /joomla (Status: 301) [Size: 309] [--> http://10.0.0.103/joomla/] /server-status (Status: 403) [Size: 275]
Conclusions
As we have seen, it is relatively easy to create a script that suits our needs. In this case, copying this script to the compromised machine (as long as it has Python3) would be enough to run it, since it obtains the dictionary via HTTP and does not make use of additional libraries. From here, you can modify it and adapt it to what you need.
It is very important to be able to build our own tools and scripts that adapt to the needs we have at each moment, because not always the existing tools are going to be able to adapt well enough to all scenarios. In addition, being fluent in scripting allows us to automate many routinary processes allowing us to spend more time on more important tasks.