 Hackatua - 19 de febrero de 2023
Hackatua - 19 de febrero de 2023Python3 HTTP Directory Lister con diccionario remoto
Cómo desarrollar un HTTP directory lister en Python3 sólo con librerías nativas y un diccionario remoto
En muchas ocasiones, tras haber conseguido vulnerar una máquina, alcanzamos nuevas subredes que hay que explorar y nos vemos obligados a trabajar desde la máquina vulnerada. Al contrario que en la máquina desde la que atacamos, en la máquina vulnerada seguramente no haya herramientas de pentesting, por lo que tendremos que buscar la forma de hacer nuestro reconocimiento sin ellas.
En estos escenarios en los que no podemos instalar herramientas tenemos que echarle imaginación y contruir la nuestras propias que se adapten a las circunstancias. Por ejemplo, de ser una máquina Linux, solemos tener a nuestro alcance el intérprete de Python ya que viene instalado por defecto en varias distribuciones. Esto nos permite desarrollar y ejecutar de manera rápida herramientas que construyamos usando ese lenguaje.
En este post veremos cómo podemos construir un script en Python3 que nos permita listar los directorios y ficheros existentes de una aplicación web usando un diccionario que se encuentre en una URL remota, y sin la necesidad de instalar ninguna dependencia o librería adicional a las que ya vienen por defecto con Python.
Construyendo el script
El script consta de 3 partes principales: la generación del diccionario URLs, la comprobación de la existencia o no existencia de las URLs generadas, y la obtención de los parámetros con los que llamamos al script y su ejecución.
El script soportará aumentar el diccionario usado agregándole extensiones de fichero a las diferentes palabras del mismo, y hará uso de varios hilos de ejecución a la hora de verificar la existencia de los recursos. De no hacer esto último, el proceso podría ser muy lento.
Para ello empezamos definiendo el intérprete, agregando las dependencias, y las variables necesarias:
#!/usr/bin/env python3 from urllib.request import urlopen, Request from urllib.error import HTTPError from queue import Queue from typing import List from re import search import sys from threading import Thread from argparse import ArgumentParser, RawDescriptionHelpFormatter AGENT = "Mozilla/5.0 (X11: Lunux x86_64: rv:19.0) Gecko/20100101 Firefox/19.0" DEFAULT_THREADS = 10
Las librerías más impotantes que usamos son urllib para realizar las peticiones HTTP, queue y threading para gestionar el multihilo, y argparse para definir los parámetros de llamada del script. También definimos el user agent que usaremos en nuestras peticiones.
Generamos el diccionario
En esta primera parte generaremos el diccionario que usará nuestro script. Este diccionario se obtiene agregando las extensiones especificadas a la hora de llamar al script a un diccionario obtenido mediante HTTP (también especificado en la llamada de script).
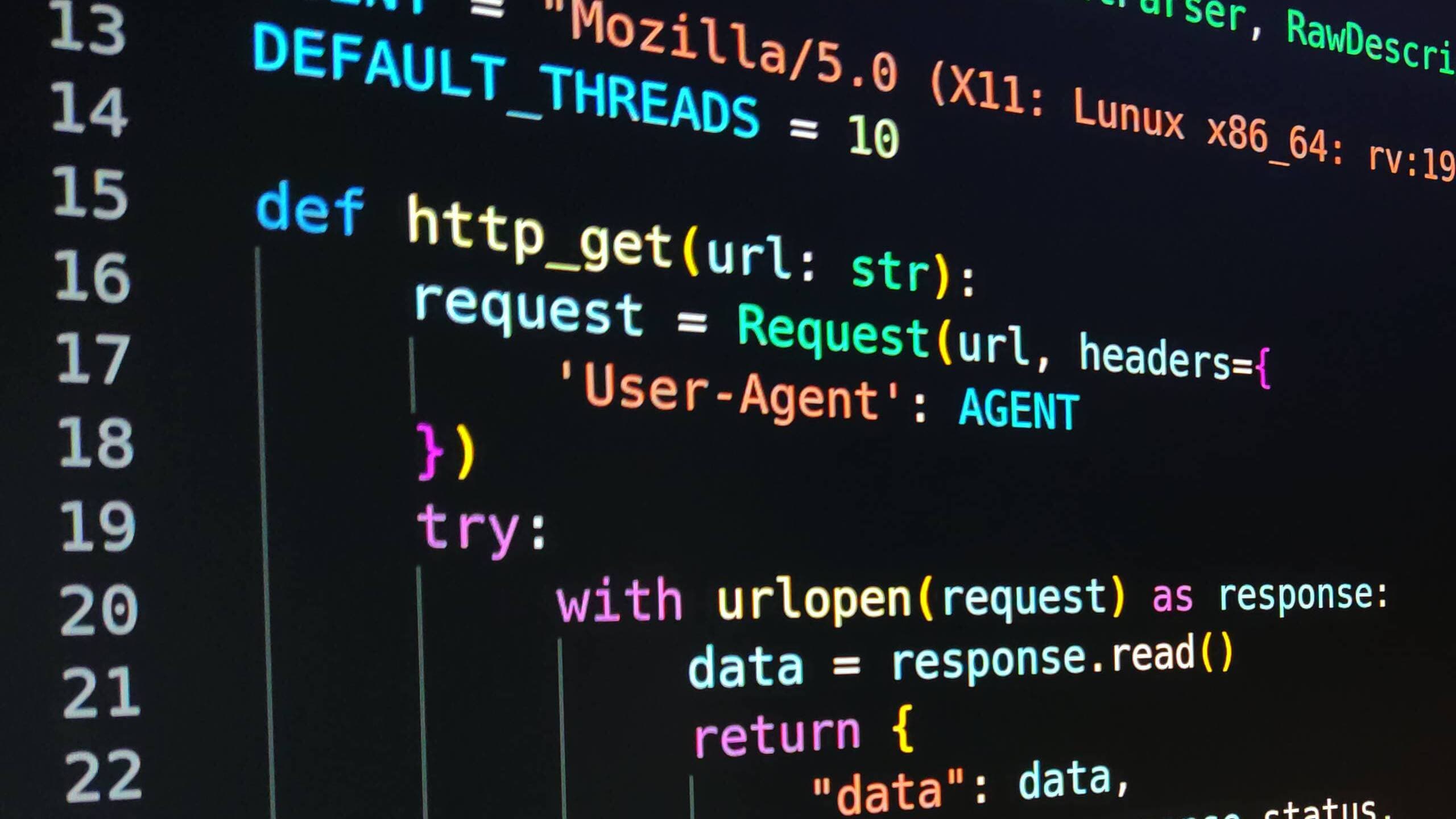
Lo primero que necesitamos es una función que nos permita hacer una petición GET mediante HTTP. Esta función se usará tanto para obtener el diccionario como para luego comprobar si existen los directorios y ficheros en la apliación web:
def http_get(url: str): request = Request(url, headers={ 'User-Agent': AGENT }) try: with urlopen(request) as response: data = response.read() return { "data": data, "status": response.status, "url": response.url } except HTTPError as error: return { "status": error.code, }
En este fragmento de código usamos la librería urlib para construir una petición HTTP al que le vamos a agregar un User-Agent, ya que muchos servicios verifican que sea un User Agent de un navegador existente. De manera adicional gestionamos los posibles errores HTTP devolviendo únicamente el código de estado que nos devuelva el servidor.
Lo siguinte que tenemos que hacer es usar este método para obtener el diccionario de la URL introducida por el usuario:
def get_dictionary(remote_dictionary_url: str) -> List[str]: response = http_get(remote_dictionary_url) data = response["data"] return data.decode("UTF-8").split("\n")
Usando la función definida anteriormente obtenemos el diccionario, lo decodificamos usando la codificación UTF-8, y creamos una lista con un elemento por cada una de las líneas del mismo (se espera un diccionario en el que cada palabra está separada por un salto de línea).
Ahora que tenemos esto listo, es hora de agregar las extensiones a las palabras del diccionario recuperado mediante el método get_dictionary:
def has_extension(word: str) -> bool: return search("(\.\w+)$", word) def get_dirs(remote_dictionary_url: str, extensions: List[str]) -> Queue: print(f"[+] Retrieving wordlist from {remote_dictionary_url} ...") dictionary = get_dictionary(remote_dictionary_url) print(f"[+] Loaded {len(dictionary)} words from {remote_dictionary_url}") print(f"[+] Building dictionary with extensions {extensions} ...") words = Queue() for raw_word in dictionary: word = raw_word.strip() if len(word) == 0 or word.startswith("#"): continue words.put(word) if not has_extension(word) and len(extensions): for extension in extensions: words.put(f"{word}.{extension}") print(f"[+] The final dictionary has approximately {words.qsize()} words") return words
En este método obtenemos el diccionario y creamos un objeto de tipo Queue, el cual nos permitirá después, mediante el uso hilos, consumirlo de manera segura.
Agregamos todas las palabras del diccionario a nuestra queue eliminando las inválidas, es decir, eliminando aquellas que sean comentarios (las que empiezan por #) o que no tengan longitud. Para cada palabra válida, generamos una palabra adicional por cada extensión.
Listamos los directorios y ficheros
Con lo hecho anteriormente ya tenemos lista la parte de obtener el diccionario que se usará durante el ataque, así que lo siguiente es crear la función que verifique si existe el fichero o directorio. Para ello haremos una función que cogerá un elemento de la queue y comprobará si existe:
def dir_test_handler(target_url: str, words: Queue): while not words.empty(): url = f"{target_url}/{words.get()}" print(f"[+] {words.qsize()} dirs left" + " " * 10, end='\r') try: response = http_get(url) except: continue status = response["status"] if status >= 200 and status < 300: final_url = response["url"] if url == final_url: print(f" [*] [{status}]: {url}") else: print(f" [*] [{status}]: {url} -> {final_url}") elif status == 401 or status == 403: print(f" [!] [{status}]: {url}") elif status >= 400 and status < 600: continue else: print(f" [?] [{status}]: {url}")
Esta función lo que hace es lo siguiente:
- Genera la URL final del fichero o directorio
- Muestra cuántas urls quedan por probar
- Hace la petición y descarta si hay algún error no controlado
- En base al status mostramos el resultado por pantalla
En caso de ser un 2XX, puede deberse porque el recurso está en la url generada, o porque ha habido una redirección. En ese caso la url y la final_url son distintas por lo que mostramos que ha habido redirección.
Los 4XX y 5XX los ignoramos, salvo que sean un 401 o 403, ya que son URLs a las que podríamos conseguir acceso si descubrimos cómo autenticarnos.
Y finalmente, cualquir código de estado diferente a éstos lo mostramos, ya que es algo raro que puede merecer la pena investigar.
Definimos los parámetros
Lo siguiente que tenemos que hacer es definir con qué parámetros se va a poder ejecutar el script. En principio me interesaría poder proporcionar:
- URL de la máquina objetivo contra la que queremos lanzar el ataque
- URL del diccionario que queremos usar como base
- Número de hilos de ejecución a usar
- Extensiones de fichero con las que extender el diccionario
Para definir estos parámetros usaremos la librería argparse, que nos permite definir todos estos parámetros de manera sencilla, y nos automatiza tanto el parseo como la opción de mostrar ayuda:
def parse_arguments(): example_text = "\n".join([ "usage:", " python3 %(prog)s -u http://10.0.0.103 -d https://..../directory-list-2.3-medium.txt -e html,txt -t 20", " python3 %(prog)s -t -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt" ]) parser = ArgumentParser( description="HTTP directory lister program that retrieves the wordlist through HTTP and only uses default Python libraries", formatter_class=RawDescriptionHelpFormatter, epilog=example_text ) parser.add_argument( "-u", "--url", type=str, help="Target URL (-u http://10.0.0.103)", required=True ) parser.add_argument( "-d" ,"--dict", type=str, help="Dictionary URL (-d -d https://.../directory-list-2.3-medium.txt)", required=True ) parser.add_argument( "-t", "--threads", type=int, help="Number of threads (-t 20)", default=DEFAULT_THREADS, required=False ) parser.add_argument( "-e", "--ext", type=str, help="File extensions to test, separated by \",\" (-e html,txt)", default="", required=False ) return parser.parse_args()
Como podemos ver hemos definido cada uno de los argumentos con sus características, y una pequña ayuda de cómo usarlo.
Ahora ya sólo nos queda definir el punto de entrada del programa:
def main(): args = parse_arguments() dirs = get_dirs(args.dict, args.ext.split(",")) print(f"[+] Ready to do directory discovery on {args.url}") print("[+] Press enter to continue") sys.stdin.readline() print(f"[+] Spawning {args.threads} threads...") for _ in range(DEFAULT_THREADS): thread = Thread( target=dir_test_handler, args=(args.url, dirs, ) ) thread.start() if __name__ == "__main__": try: main() except KeyboardInterrupt: print("[!] Exiting...") sys.exit(0)
En nuestra función main parseamos los parámetros con los que hemos llamado el script, generamos el diccionario, mostramos la información del ataque que se va a hacer y esperamos a la confirmación del usuario. Tras la confirmación creamos el número de hilos que se ha indicado y comienza el ataque.
De manera adicional se captura la excepción de teclado producida al presionar Ctrl + c para poder salir del programa sin ver la excepción.
Con esto último ya tendríamos el programa listo para ejecutar. El código fuente al completo está disponible en:
Probando el script
Lo primero que podemos hacer es ver el menú de ayuda de nuestro script:
python3 remote-dictionary-dirlister.py -h # or python3 remote-dictionary-dirlister.py --help
Resultado:
usage: remote-dictionary-dirlister.py [-h] -u URL -d DICT [-t THREADS] [-e EXT] HTTP directory lister program that retrieves the wordlist through HTTP and only uses default Python libraries options: -h, --help show this help message and exit -u URL, --url URL Target URL (-u http://10.0.0.103) -d DICT, --dict DICT Dictionary URL (-d -d https://.../directory-list-2.3-medium.txt) -t THREADS, --threads THREADS Number of threads (-t 20) -e EXT, --ext EXT File extensions to test, separated by "," (-e html,txt) usage: python3 remote-dictionary-dirlister.py -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt -e html,txt -t 20 python3 remote-dictionary-dirlister.py -t -u http://10.0.0.103 -d https://.../directory-list-2.3-medium.txt
Ahora que ya hemos verificado que la ayuda funciona, lo que podemos hacer es probar el script contra la máquina Naguini de Vulnhub, la cual ya hemos resuelto aquí.
Para ello desplegamos la máquina y ejecutamos el script. En este caso vamos a usar el diccionario directory-list-2.3-medium del repositorio SecLists de Daniel Miessler, con 20 hilos, y con las extensiones html y txt.
remote-dictionary-dirlister.py -u http://10.0.0.103 -d https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt -e html,txt -t 20
Resultado:
[+] Retrieving wordlist from https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt ... [+] Loaded 220561 words from https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt [+] Building dictionary with extensions ['html', 'txt'] ... [+] The final dictionary has approximately 661635 words [+] Ready to do directory discovery on http://10.0.0.103 [+] Press enter to continue [+] Spawning 20 threads... [*] [200]: http://10.0.0.103/index.html [*] [200]: http://10.0.0.103/note.txt [*] [200]: http://10.0.0.103/joomla -> http://10.0.0.103/joomla/ [!] [403]: http://10.0.0.103/server-status
Si lo comparamos con lo obtenido con Gobuster en la resolución de la máquina Nagini nuestro script no tiene nada que envidiarle. Este fue el resultado obtenido:
/index.html (Status: 200) [Size: 97] /note.txt (Status: 200) [Size: 234] /joomla (Status: 301) [Size: 309] [--> http://10.0.0.103/joomla/] /server-status (Status: 403) [Size: 275]
Conclusiones
Como hemos podido ver, es relativamente sencillo crear un script que se adapte a nuestras necesidades. En este caso, con copiar este script en la máquina comprometida (siempre y cuando tenga Python3) sería suficiente para ejecutarlo, ya que obtiene el diccionario mediante HTTP y no hace uso de librerías adicionales. A partir de aquí, puedes modificarlo y adaptarlo a lo que necesites.
Es muy importante ser capaz de contruir nuestras propias herramientas y scripts que se adapten a las necesidades que tenemos en cada momento, porque no siempre las herramientas existentes se van a poder adaptar lo suficiente a todos los escenarios. Además, tener soltura a la hora de programar scripts nos permite automatizar muchos procesos rutinarios permitiéndonos dedicar más tiempo a tareas más importantes.